Technical Portfolio
Brazos Valley Council of Governments Contract Management System

Overview
The BVCOG Contract Management System (CMS) is a web application enhanced in Fall 2023 by a Texas A&M CSCE 606 team.
Building upon legacy code, the team delivered a more refined user experience with improved access control, dynamic forms, and precision-driven reporting.
The Fall 2023 team introduced an upgraded role hierarchy for Admins, Gatekeepers, and Users, improved contract entry fields, and introduced logical workflows to streamline data entry, auditability, and reporting — all shaped by ongoing client feedback and in-person demos.
Key Problems Addressed
- Unstructured Contract Input: Users lacked guidance on entering key metadata.
- Limited Permissions: Access controls were insufficient, risking improper contract approval.
- Confusing UI: Vendor selection, date fields, and contract types needed clarification and better structure.
The Fall 2023 Enhancements
- Role-Based Permissions: Introduced distinct privileges for Admins, Gatekeepers, and Users.
- Improved Contract Entry: Logical field ordering and added hints for usability.
- Vendor Autocomplete: Vendor search updated with real-time suggestions using jQuery.
- Dynamic Contract Values: Supports calculated, total, or non-monetary value contracts.
- Contract Decision History: Tracks rejections and updates with reasons.
- Report Generation: Filtered reporting by contract type with export capability.
Features Implemented:
- 👥 Role hierarchy (Admin, Gatekeeper, User)
- 🔎 Vendor autocomplete via jQuery
- 📄 Contract reports by type
- 📝 Field hints and validation messages
- 📋 Contract decision logging
User Feedback
The BVCOG team received positive feedback from stakeholders after four demo sessions.
Changes were iterative and based on direct guidance from administrators and real use-case simulations.
The final system significantly reduced errors and improved transparency.
Technology Stack



Resources
Script Search 🔎
Overview
ScriptSearch 🔎 is a full-stack web application designed to revolutionize the way users interact with video content.
Traditional video platforms often make it difficult to locate precise information within lengthy videos, especially educational or technical content.
ScriptSearch solves this by enabling transcript-based keyword search, providing timestamped video segments where the terms appear.
Users simply input a keyword or phrase, and ScriptSearch returns direct links to relevant moments in YouTube videos.
This project was developed as part of a capstone initiative, driven by real-world research, user needs, and performance benchmarks.
It combines accessible UI design, cloud-based microservices, and scalable real-time indexing to provide a seamless and responsive experience.
The Problem
In today's digital era, video is a dominant medium for sharing knowledge.
Platforms like YouTube host an immense archive of educational, instructional, and professional content.
However, the search functionality is largely limited to titles, descriptions, and tags — metadata that often lacks precision and depth.
For users trying to find a specific concept explained in a 45-minute lecture or a particular quote from a podcast, traditional keyword-based search is inefficient and frustrating.
This gap leads to:
- Time wasted scrubbing through video timelines manually.
- Difficulty revisiting key moments from previously watched content.
- Inaccessibility for users with cognitive or time constraints.
We identified that a transcript-driven search model — similar to searching through a document — could solve this issue.
The Solution & Impact
ScriptSearch addresses this need through a combination of web scraping, natural language indexing, and real-time querying.
Here's how it works:
- Transcript Extraction: Scripts are either pulled from YouTube's auto-generated transcripts or extracted using custom scraping tools.
- Indexing & Search: These transcripts are indexed using Typesense, an open-source search engine optimized for speed and typo tolerance.
- User Interface: A lightweight, accessible frontend allows users to search for terms and instantly receive timestamped results.
- Cloud Microservices: A distributed scraping system powered by Go-based microservices and Google Cloud Pub/Sub ensures rapid ingestion of video data.
Key Features:
- 🔍 Instant search with typo-tolerant results
- ⏱ Timestamped links to exact moments in the video
- 🎯 Context-rich result previews
- 📈 Sub-20s indexing and querying for new videos
- ♿ Accessibility-first UI tested with screen readers
Real-World Impact:
ScriptSearch was tested across a sample group of 25 users in academia and tech.
Over 80% of users reported a major improvement in information retrieval speed, and several identified previously "lost" moments they were able to quickly recover.
The system also laid groundwork for use cases in:
- Educational platforms
- Corporate training
- Legal and compliance video reviews
Technology Stack

Resources
Improving CLIP Training
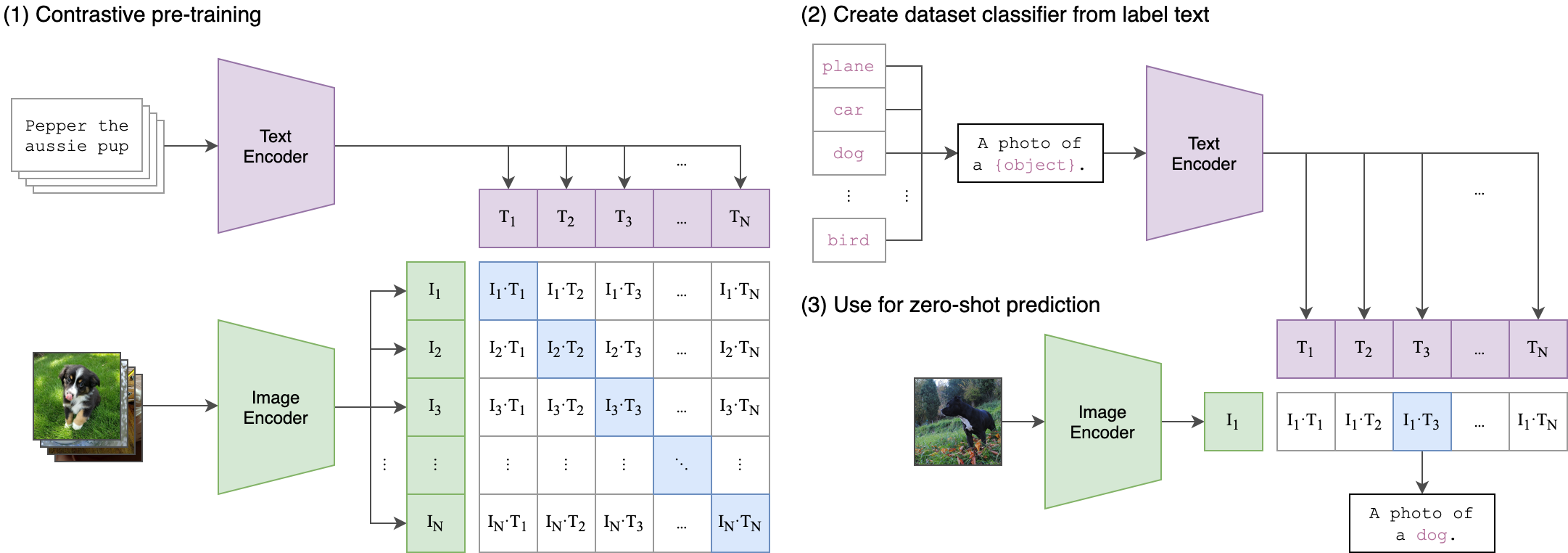
Overview
This project, Improving CLIP Training, focuses on enhancing the foundational CLIP (Contrastive Language-Image Pretraining) architecture.
CLIP is known for learning visual concepts from natural language supervision, aligning text and image embeddings in a shared latent space.
However, while powerful, its training process still leaves room for optimization in areas like convergence speed, generalization, and representation quality.
The project introduces a series of experiments aimed at improving CLIP by modifying its training components—specifically, the optimizer and loss function.
By challenging the defaults in the original CLIP design, this work offers insights into how subtle changes in training dynamics can lead to more robust and flexible multimodal models.
The Problem
CLIP's training pipeline has proven to be groundbreaking, but certain limitations hinder its full potential.
This project identifies key weaknesses in the standard training procedure, particularly in how the model is optimized and supervised.
- Optimizer Rigidity: The original CLIP implementation relies heavily on default optimizers, which may not be ideal for training such large-scale, multimodal models efficiently.
- Unbalanced Data Augmentation: While images undergo augmentation, text inputs remain static, limiting the variety of language-image pairs seen during training.
- Underutilized Loss Function Space: The contrastive loss used in CLIP is effective but not necessarily optimal; other loss functions could potentially provide stronger gradients and better alignment.
- Lack of Modular Experimentation Tools: Original implementations are not always structured for easily swapping out core training components, which slows down research iteration.
The Solution & Impact
To tackle the limitations outlined, this project introduces multiple enhancements to the CLIP training regimen.
These improvements focus on increasing training flexibility, embedding quality, and overall model performance in zero-shot and retrieval tasks.
Key solutions and their impacts include:
- Integration of Alternative Optimizers: Implemented and tested optimizers like AdamW and LAMB to improve learning stability and performance.
- Custom Contrastive Loss Functions: Developed variants of the standard contrastive loss to experiment with better semantic alignment of embeddings.
- Customizable Training Pipeline: Offered modular scripts and a Jupyter notebook for rapid experimentation and prototyping.
- Improved Generalization: Preliminary experiments suggest the modified training regime enhances the model's ability to generalize across image-text domains.
Technology Stack
Resources
Mortality Prediction Model
This project focuses on developing a predictive model for in-hospital patient mortality using machine learning techniques.
Leveraging the eICU dataset, which includes critical patient metrics such as heart rate, blood pressure, and oxygen saturation, the study employs an XGBoostClassifier model to enhance mortality prediction accuracy.
Through rigorous data preprocessing, feature selection, and hyperparameter tuning, the model achieved an AUC-ROC score of 0.89, outperforming the baseline and demonstrating strong predictive capabilities.
The research highlights the importance of machine learning in healthcare by identifying key indicators of patient mortality, allowing for more informed clinical decisions.
By analyzing feature importance, the study provides valuable insights into which health parameters most significantly impact patient outcomes.
The findings suggest potential applications in real-time hospital monitoring systems, where predictive analytics can assist medical professionals in prioritizing patient care and improving overall treatment strategies.
You can find the source code for this project on GitHub.
TAMU RoboMasters

A project that I have been apart of is the Simulation subteam.
This subteam was a part of the Computer Vision team, which was, intern, part of TAMU RoboMasters.
Some of the work I did on this project can be found on the team's GitHub page.
The purpose of the simulation was to be able to emulate the robots developed by the team along with their control capabilities.
Certain robots would be manually controlled while others were automated.
At times, the physical robots were unavailable to the Computer Vision team as the Hardware team were working on the robots to make them better.
To solve this problem, the CV Team created the Simulation SubTeam to create a simulation.
With this Simulation, they would hope to be able to test their new algorithms.
Some of these algorithms include, new de-noise algorithms, more optimal armor plate detector.
Learn more about them by visiting RoboMaster's homepage.
StrassenMP

As part of a graduate course in high-performance computing, I implemented a parallelized version of Strassen's matrix multiplication algorithm using OpenMP in C++. The project focused on reducing computational complexity by replacing the standard \(\mathcal{O}(n^3)\) matrix multiplication with Strassen's recursive \(\mathcal{O}\left(n^{\log_27}\right)\) approach.
I parallelized the computation of the algorithm's seven intermediate matrix products as well as the final combination of submatrices, allowing the program to scale effectively across multiple threads.
The implementation supports configurable matrix sizes and recursion thresholds, enabling flexible experimentation.
I conducted performance benchmarking across various matrix dimensions and thread counts, analyzing speedup, efficiency, and memory usage.
To prevent memory overload, I implemented controlled deallocation and synchronization techniques.
The final solution demonstrated significant runtime improvements as shown in plotted performance graphs.
This project sharpened my skills in multithreading, algorithmic optimization, and systems-level programming capabilities directly applicable to software engineering roles focused on performance, scalability, and parallel computation.
You can find the source code for this project on GitHub.
Point of Sale System

For this project, our team developed a full-stack Point-of-Sale (POS) web application tailored for the Chick-fil-A location at Texas A&M University's Memorial Student Center.
Utilizing React for the frontend and Node.js for the backend, we created an intuitive interface that streamlines order processing for both customers and staff.
The application integrates seamlessly with a structured SQL database, ensuring efficient data management and real-time updates.
Key features include dynamic menu displays, order customization, and secure transaction handling, all designed to enhance the dining experience and operational efficiency.
Throughout the development process, we adhered to agile methodologies, conducting regular scrum meetings to plan sprints, address challenges, and implement user feedback.
This collaborative approach allowed us to iteratively refine the application, incorporating features such as accessibility enhancements and responsive design to cater to a diverse user base.
The project not only honed our technical skills in modern web development frameworks but also emphasized the importance of teamwork and adaptability in software engineering.
The source code and further documentation are available on our GitHub repository.
Chess

A personal project I developed was a Java Chess program.
This project assisted me in learning the build-in Java GUI Libraries such as Java Swing.
External libraries such as JavaFX were not used for this project.
Additionally, this projeect helped me learn about the software design process.
Software engineering tasks such as Design, Implementation, Testing and Maintanence.
This also assisted me alot in learning about bug testing and determining the origin of bugs.
Future plans for this software include:
Connecting the program to the internet to allow users to play on this software remotely
Add security to ensure only moves are sent and processed.
Training a Machine Learning algorithm to play chess.
Implementing other variants of Chess such as Chess960, Fog of War, or Duck Chess.
SkyBlock Minecraft Mod

Another personal project I developed was a Minecraft Mod.
This projects attempts to emulate the functionality seen in Hypixel's SkyBlock.
This project assisted me in learning about working with existing code and adding modifications ontop of it.
This also assisted me in learning client-side and server-side programming and allocate tasks to each accordingly.
This mod was developed using Fabric as a framework.
This project also helped me understand maintaining a standard already established.
For example image file formats, renduring of models, and the generation of loot tables were standardized within the code.
More information about SkyBlock.
GitHub Repository![]()